DINO-WM: World Models on Pre-trained
Visual Features enable Zero-shot Planning
New York University1
Meta-FAIR2
Abstract
The ability to predict future outcomes given control actions is fundamental for physical reasoning. However, such predictive models, often called world models, remains challenging to learn and are typically developed for task-specific solutions with online policy learning. To unlock world models' true potential, we argue that they should 1) be trainable on offline, pre-collected trajectories, 2) support test-time behavior optimization, and 3) facilitate task-agnostic reasoning.
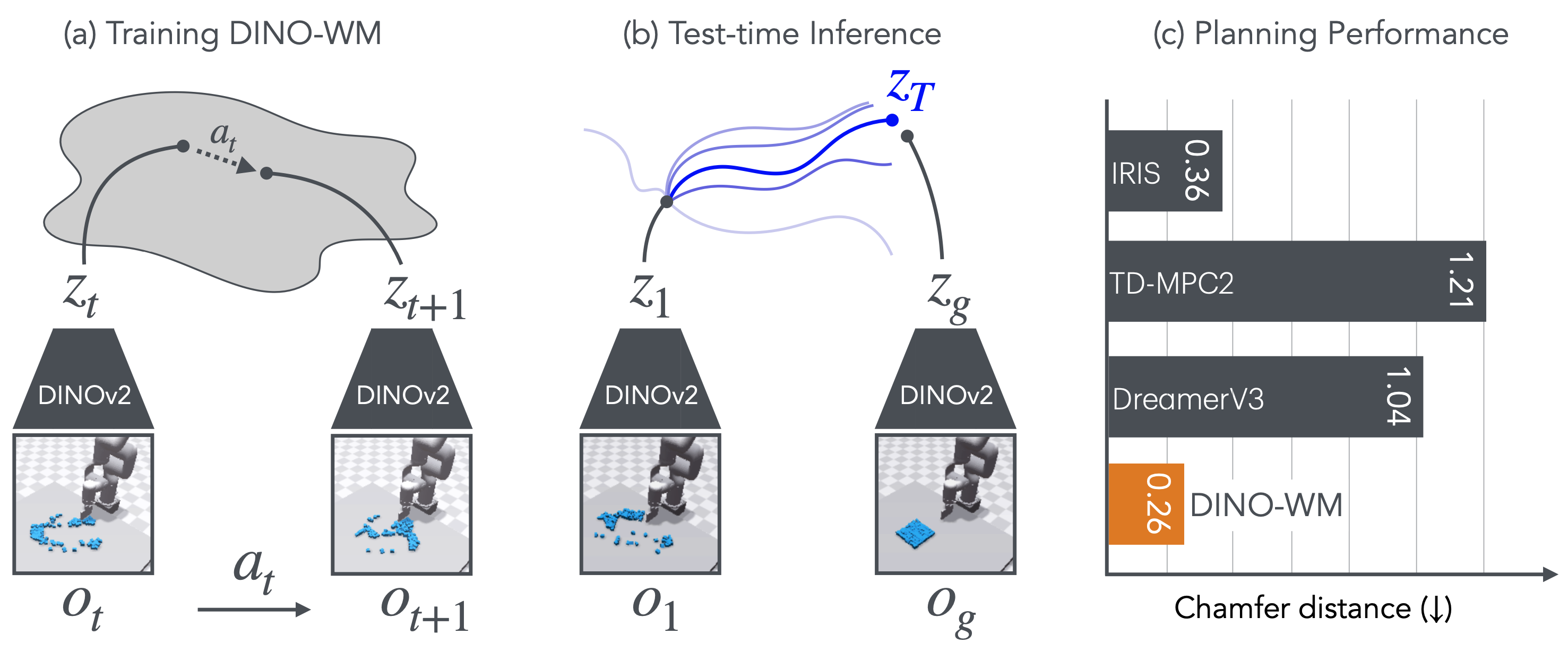
To this end, we present DINO World Model (DINO-WM), a new method to model visual dynamics without reconstructing the visual world. DINO-WM leverages spatial patch features pre-trained with DINOv2, enabling it to learn from offline behavioral trajectories by predicting future patch features. This allows DINO-WM to achieve observational goals through action sequence optimization, facilitating task-agnostic planning by treating goal features as prediction targets. We demonstrate that DINO-WM achieves zero-shot behavioral solutions at test time on six environments without expert demonstrations, reward modeling, or pre-learned inverse models, outperforming prior state-of-the-art work across diverse task families such as arbitrarily configured mazes, push manipulation with varied object shapes, and multi-particle scenarios.
Method
In this work, we present a new and simple method to build task-agnostic world models from an offline dataset of trajectories. DINO-WM models the world dynamics on compact embeddings of the world, rather than the raw observations themselves. For the embedding, we use pretrained patch-features from the DINOv2 model, which provides both a spatial and object-centric representation prior. We conjecture that this pretrained representation enables robust and consistent world modeling, which relaxes the necessity for task-specific data coverage. Given these visual embeddings and actions, DINO-WM uses the ViT architecture to predict future embeddings. Once this model is trained on the offline dataset, planning to solve tasks is constructed as visual goal reaching, i.e. to reach a future desired goal given the current observation. Since the predictions by DINO-WM are high quality, we can simply use model predictive control with inference-time optimization to reach desired goals without any extra information during testing.
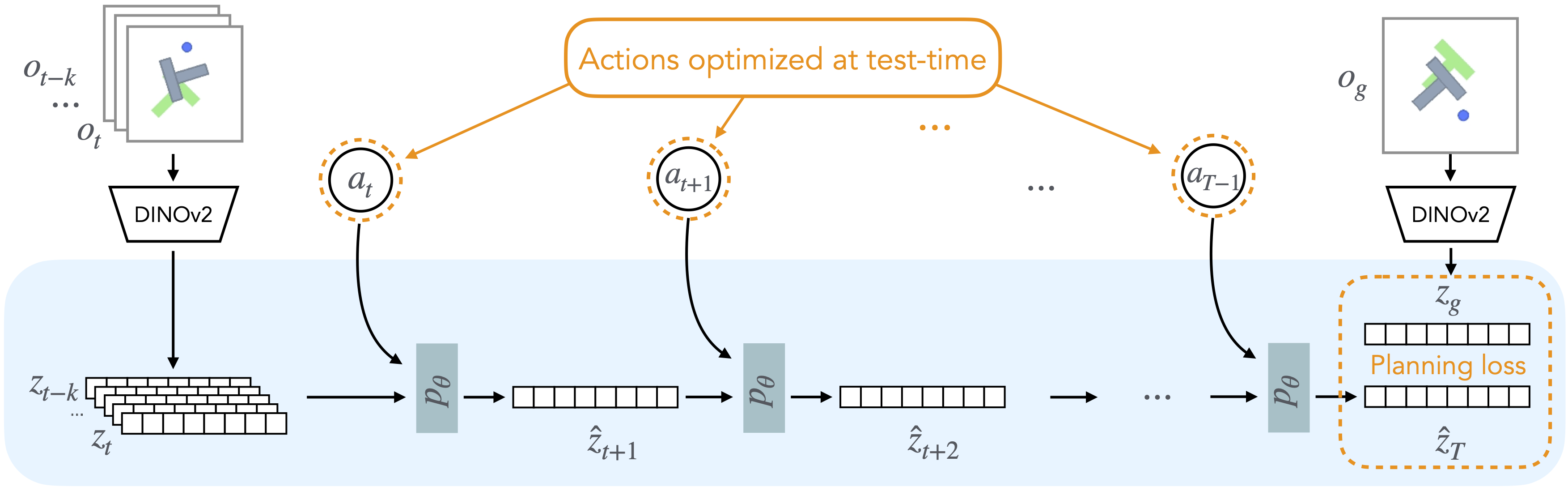
Optimizing Behaviors with DINO-WM
*For all the images and videos below, the top row shows ground truth rollouts in the environment, while the bottom row presents world model-imagined rollouts. The images on the right represent the goal states in both cases.
PushT
Wall
PointMaze
Rope
Granular
Reacher
Comparing planning performance with baselines
PushT: horizon = 25
Ours
DINO CLS
Dreamer V3
IRIS
Granular:
Ours
DINO CLS
R3M
ResNet
DM Control Reacher:
Ours Success
Ours Failure
Dreamer V3 Success
Dreamer V3 Failure
Ours
DINO CLS
Dreamer V3
IRIS
Ours
DINO CLS
R3M
ResNet
DM Control Reacher:
Ours Success
Ours Failure
Dreamer V3 Success
Dreamer V3 Failure
Ours Success
Ours Failure
Dreamer V3 Success
Dreamer V3 Failure
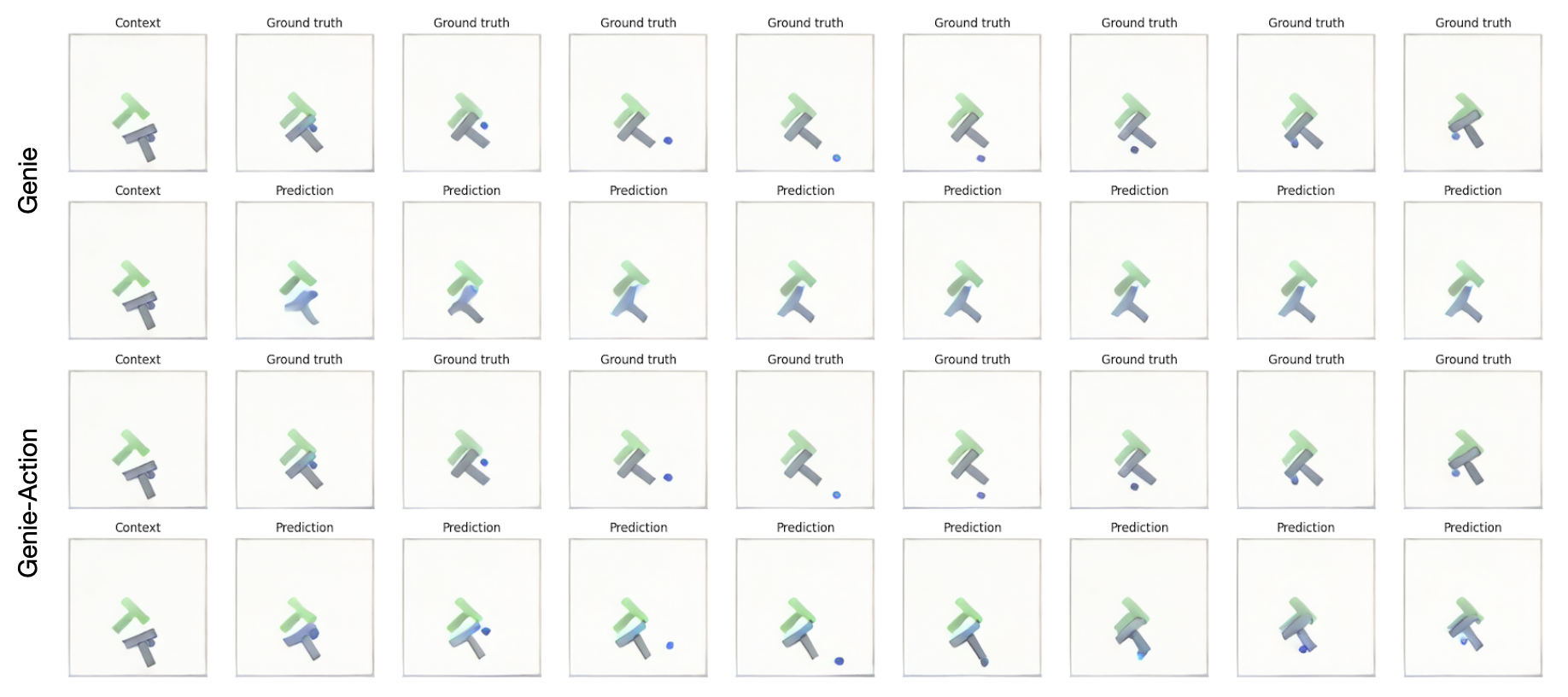
Unconditioned DINO-WM on CLEVRER
*For the videos in this section, the top row shows ground truth rollouts in the environment, while the bottom row presents world model-imagined rollouts.
1-frame rollouts are conditioned on the first frame only, while 3-frame rollouts are conditioned on the first three frames. This allows the model to better capture physical properties like velocity and trajectories. This added context improves prediction accuracy, whereas conditioning on a single frame leads to open-ended assumptions about object movements and predictions. Both are taken from the validation set.